可视化目标用户日、月、年度微博点赞数、转发数 依据目标用户原创微博所@用户,可视化用户好友关系图 设置评论数阈值,爬取目标用户热门微博下热评 统计目标用户热门微博下热评次数较多用户,挖掘目标用户狂热粉丝
”爬虫 微博文本 可视化、 文本分析“ 的搜索结果
大数据毕业设计hadoop+spark+hive微博预警系统 微博数据分析可视化大屏 微博情感分析 微博爬虫 微博大数据 微博推荐系统 微博预测系统 计算机毕业设计 知识图谱 机器学习 深度学习
基于Python的微博舆情数据爬虫可视化分析系统,结合了NLP情感分析、爬虫技术和机器学习算法。该系统的主要目标是从微博平台上抓取实时数据,对这些数据进行情感分析,并通过可视化方式呈现分析结果,以帮助用户更好...
包括爬虫,数据预处理,文件管理,可视化,文本情感分析. 爬取:评论地址,爬取次数,爬取什么评论,爬取时间,保存名称 文件管理:爬取过程有问题或者查看数据,删除文件,重命名,下载文件,上传文件 处理:简单...
微博数据爬取:项目利用爬虫技术,从微博平台获取需要分析的微博公开数据,并将爬取到的数据保存到MySQL数据库中。 数据浏览:项目提供一个用户界面,允许用户浏览和搜索已爬取的微博数据。用户可根据时间、关键词...
基于Python的网络爬虫及文本可视化
练手必备!微博热搜爬虫项目,含pillow绘图及selenium的使用。
这里写自定义目录标题爬取微博实时热搜数据可视化分析一、爬取数据1.1 Spider主要函数1.2 根据微博一分钟更新一次的状态进行爬虫二、可视化 爬取微博实时热搜数据可视化分析 一、爬取数据 1.1 Spider主要函数 1.2 ...
Python爬虫数据可视化分析大作业,利用Python网络爬虫对京东商城中指定商品下的用户评论进行爬取,对数据预处理操作后进行文本情感分析并可视化显示。
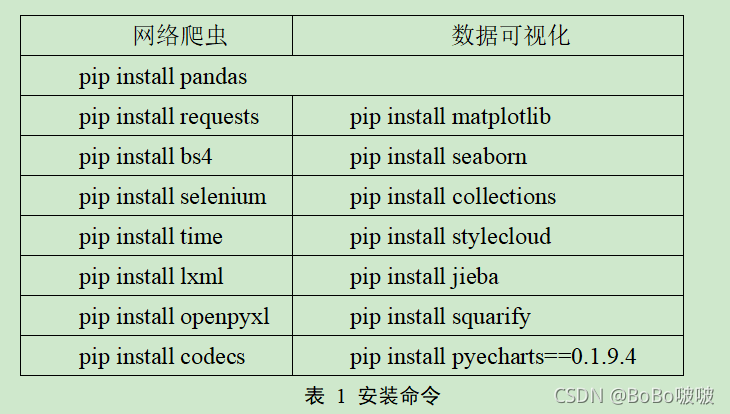
Python语言、Flask框架、MySQL数据库、requests网络爬虫技术、scikit-learn机器学习、snownlp情感分析、词云、舆情分析3、项目说明1.开发工具本项目主要采用 PyCharm 开放平台利用 Python 语言来实现的。PyCharm 是...
一般m站都以m开头后接域名, 此次针对某微博用户进行微博数据可视化,选取m.weibo.cn去分析微博的HTTP请求。 (1) 需要的模块 import urllib import urllib.request import time import json impo
微博爬虫/数据分析/可视化
标签: python
微博的数据分析以及可视化 最近在学习数据分析,数据挖掘以及数据可视化的内容,之前断断续续地采集了接近1亿条微博数据,还有几十万的用户的信息。所以筛选了一部分数据来分析分析。下面的内容大多以《广州发布》...

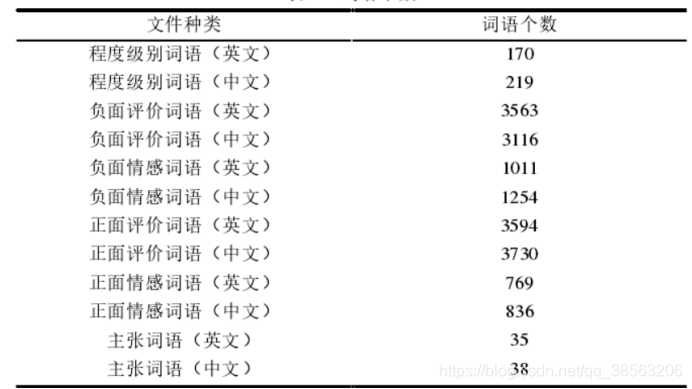
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
微博炫酷可视化音乐组合版来了! 项目介绍 背景 现阶段,微博、抖音、快手、哗哩哗哩、微信公众号已经成为不少年轻人必备的“生活神器”。在21世纪的今天,你又是如何获取外界的信息资源的?相信很多小...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
通过对微博、豆瓣、知乎等社交平台进行考察分析,微博以活跃用户多、讨论热度高、公众关注度广等特点成为了本小组的第一首选。因此我们决定选用微博评论来作为数据分析主要数据来源。针对微博评论,我们通过词频分析...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬取新浪微博用户信息及微博内容并进行可视化分析
TAPTAP游戏评论的文本挖掘(完整源码项目说明)(包括APP爬虫、数据清洗、pyecharts可视化、pytorch框架下LSTM模型情感分析).zipTAPTAP游戏评论的文本挖掘(完整源码项目说明)(包括APP爬虫、数据清洗、pyecharts...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
数据可视化分析1. 数据爬取1.1 评论爬取1.2 用户信息爬取1.3 数据清洗 & 可视化 1. 数据爬取 爬虫部分主要是调用官方API,本次用到的API主要有两个: 获取评论: ...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...

推荐文章
- 联邦学习综述-程序员宅基地
- virtuoso--工艺库答疑_tsmc mac-程序员宅基地
- C++中的exit函数_c++ exit-程序员宅基地
- Java入门基础知识点总结(详细篇)_java基础知识重点总结-程序员宅基地
- 【SpringBoot】82、SpringBoot集成Quartz实现动态管理定时任务_springboot集成quratz 实现动态任务调度-程序员宅基地
- testNG常见测试方法_idea_java_testng 测试-程序员宅基地
- Debian11系统安装-程序员宅基地
- Centos7重置root用户密码_centos7更改root密码-程序员宅基地
- STM32常用协议之IIC协议详解_正点原子stm32 iic-程序员宅基地
- 【视频播放】Jplayer视频播放器的使用_jplayer 播放amr-程序员宅基地